What will become possible when conversational AI can ‘see’?
Websites and social media are increasingly dominated by photos and videos, and many devices now have cameras that can ‘see’ the world around us. Imagine when virtual agents are able to describe images and reference the world they see either on a screen or through a camera. This will make AI conversations more interactive, useful, and engaging for everyone – including people with visual impairments. In a smart space environment, visitors will have virtual guides they can talk to in real-time about the space as they see it. And being able to use your voice to communicate and interact with what you’re viewing in a VR world will add a whole new dimension to immersive experiences.
We’re now living in a visual age, and we need our voice assistants to be able to become an active part of it.
Why ‘seeing’ is important to conversation
Often our conversations with friends, family and colleagues are triggered by something we can see (or can’t see). As we seek to make Alana conversations more natural and human-like, the ability to respond to visual cues and incorporate image and spatial references into AI voice exchanges is an important new development. This is why we believe the evolution of visual dialogue is so important to the future of conversational AI.
Many of us now rely on an army of speech-controlled virtual assistants to help us to navigate a multitude of everyday problems. From turning on lights to predicting our journey times. But there are still occasions where chatbots and conversational AI companions fail to deliver the flawless user experience we crave. A common reason for this is that these devices can’t see. This prevents them from interpreting visual information or responding to spatial questions.
But this is changing – our research team is helping Alana to see the world in a similar way to humans. This involves embedding within our technology the ability to engage in interactive visual conversations
What is visual dialogue?
Visual dialogue describes conversations where visual and spatial information adds important context or is the focal point of an enquiry.
In our daily lives, we naturally use visual descriptions to describe our situation and spatial reference points to explain our needs. But most conversational AI agents can’t interact with a human in this way – they can’t see things the way we can. This means for most systems the following types of user questions and commands are currently off limits:
“Where are my keys?”
“What’s in this bottle I’m holding?” / “What does this say?”
“Where’s the nearest exit?” / “Where can I sit down?”
“Show me the video on the top left of the screen.” / “the one with the big shark”
If you consider these questions and commands, it’s clear sometimes we don’t just need our voice-enabled devices to listen. In some scenarios, we also need them to see the situation – to recognise and act on a visual cue or maybe describe something like an image or object.
Visual dialogue empowers AI agents to interact with humans in natural, conversational language about visual content. For example, this could be detecting an image or object, and then answering a follow-up question related to it.
Training conversational AI to see with computer vision
We want Alana to be able to take a conversational question about something visual and generate a natural language answer in response. To do this, we’re training Alana to see using computer vision techniques.
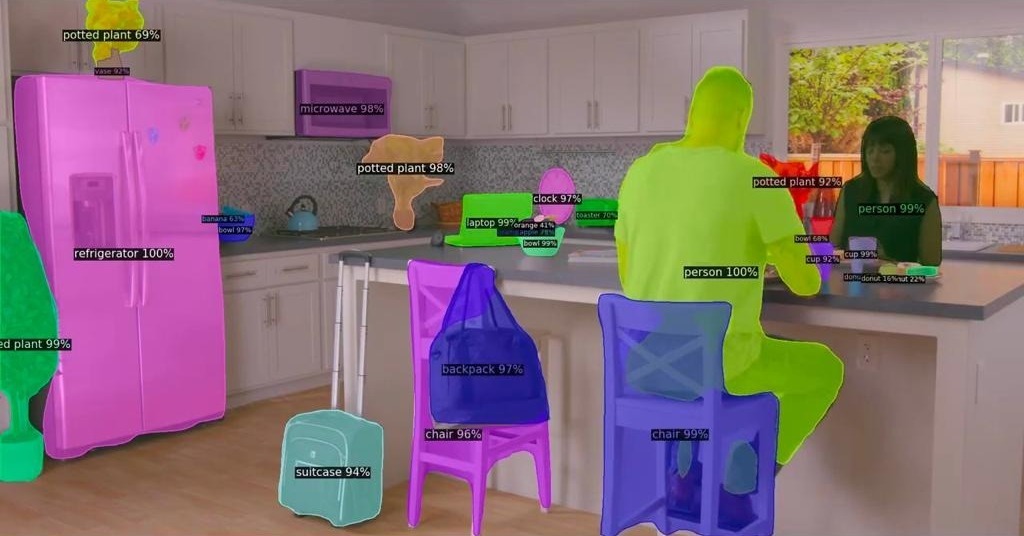
Computer vision is a subfield within artificial intelligence and machine learning. It uses deep learning to enable computers to identify images, objects and other visual inputs and then teaches it how to respond based on this information. To give Alana the capability to interpret visual or spatial information and answer a natural language question about an image, physical environment, location or object, we’re embedding computer vision techniques into our conversational AI model.
Five core computer vision capabilities need to be embedded within conversational AI to replicate the way the human vision system works:
- Object recognition: Detects, defines, and identifies objects.
- Depth estimation: Estimates the spatial structure of a scene or environment.
- Image segmentation: Divides a visual into classifiable parts by identifying boundaries and how they relate to one another.
- Relationship predictions: Predicts the spatial relationship between objects.
- Text recognition: Reads the text on an object.
How visual dialogue fits into our vision for Alana
Making life simpler for our users has always been a key part of Alana’s mission, and visual dialogue was a missing link. Injecting visual and spatial information into our conversations definitely bridges an important gap in human-to-computer communication.
The most significant and powerful application of visual dialogue we’ve seen so far is how it makes Alana more inclusive. For example, we’re working closely with the RNIB, the UK’s leading organisation for people with sight problems, to launch the first conversational AI companion specifically designed to support people living with sight loss. From identifying objects and landmarks to directing a partially-person safely to a destination, to helping them to cook a meal or helping them to interact with image-led social media posts – by giving Alana computer vision, our aim is to give people with low vision independent access to parts of the online and offline worlds that have previously been difficult for them to navigate. This for us encapsulates how life-changing visual dialogue will be.
The blind and visually impaired community are certainly a community that will benefit significantly from this development in conversational AI. But this is just one example. Visual dialogue will open up many important opportunities for conversational AI. And not just in the real world.
Virtual reality (VR) and augmented reality (AR) are projected to grow exponentially in the coming years and visual dialogue will add a vital new dimension to how we interact while in these immersive experiences. For example, by enabling users to use their voice to interact more freely while they’re wearing a VR headset, people will be able to use speech to explore and interact with a virtual world in a similar way to how they would in real life.
How could visual dialogue help you?
The visual advancements we’re adding to Alana are an important demonstration of how we continue to make strides forward in advancing conversational AI. To discuss how could visual dialogue help you book a consultation: https://alanaai.com/contact/